Let me know if you had this issue before, you a business problem which is data driven, so you think approaching the problem with a data driven solution. You start reviewing articles in the literature and on the web, and you found this new machine learning model which is beating any other learning algorithm in most of the Kaggle competitions and you found that there is a stable community and stable version of the algorithm so you’re saying to yourself why not use this model in your problem?! After all, it’s is quite tempting, and you don’t want to be left behind.
You start programming the solution, and to your amazement you need to represent your data in a way that the algorithm requires for it to work. The representation is not straight forward, so it takes a couple of hours or days you work over the data representation. Now, it’s not over yet, there is a tendency for algorithms to be more complex as time goes by, because technology often enables new computation capabilities That are more advanced then does of older traditional algorithms, so the computation complexity increase, which means more running time for learning.
Now, after all this extra hard work another issue to consider when using this new “black-box” algorithm, is how are you going to interpret the results? In most cases you have to show your results and explain it to people with no background in machine learning, you could something on the line of: “it works, and that’s what matters”, but you will always hit a glass ceiling and swim around your solution like a fish in a vast ocean, not knowing what affects what, why and in what magnitude.
All this build up leads us to what we call: “baseline”, the most simple, fast and naïve learning algorithm that you suspect that will fit the problem. This algorithm is the first one you try, you’ll be surprised how efficient and significant this baseline will be turn out to be, I’ve seen allot of cases where the baseline was better than the more advanced, complex so could more promising algorithm. If you start from the complex algorithm you are not only risking wasting allot of hours to prepare the data, model and find creative ways to interpret your results. The baseline will always help you see if your extra work over the new model is worth your resources or not. Please, use it.
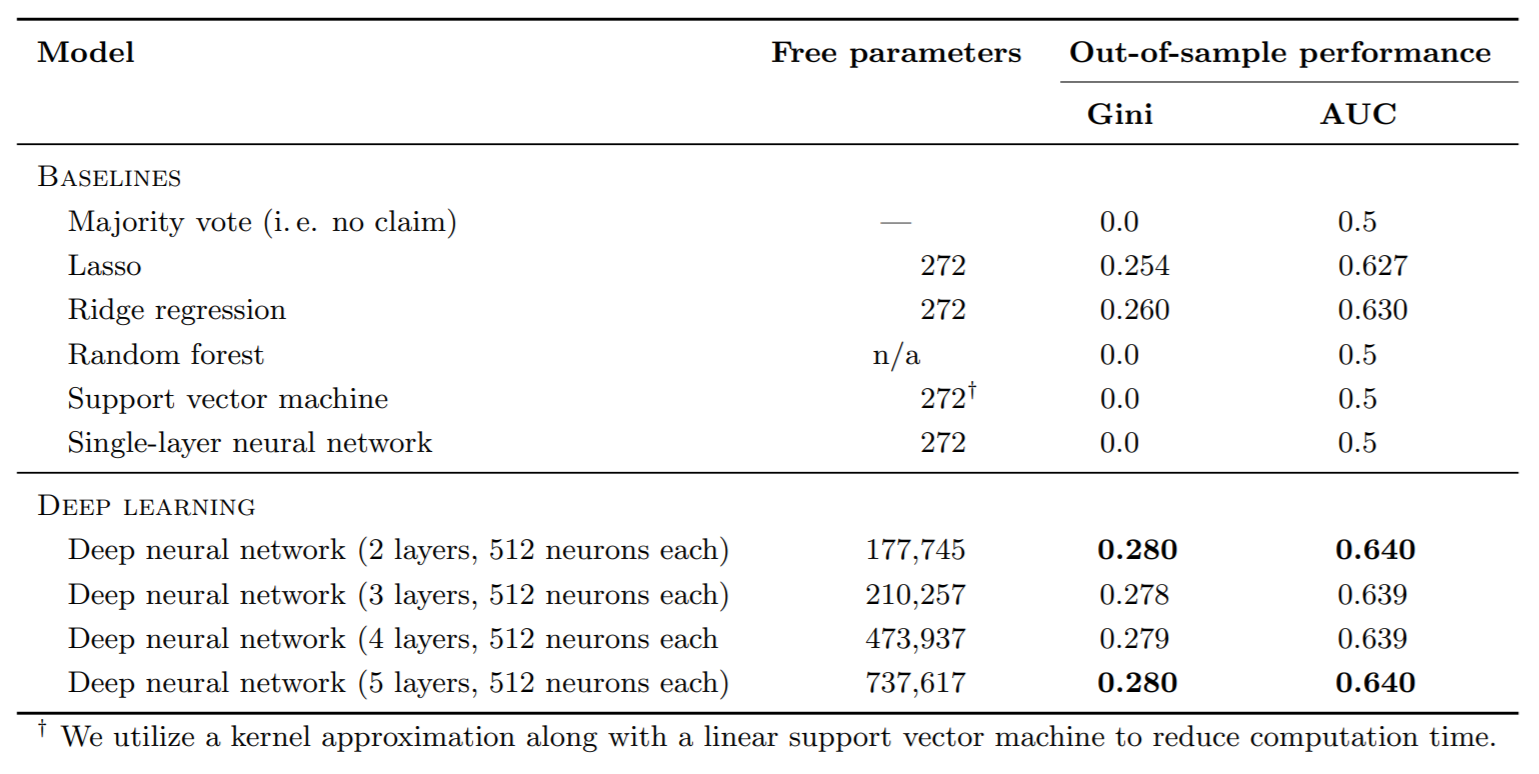
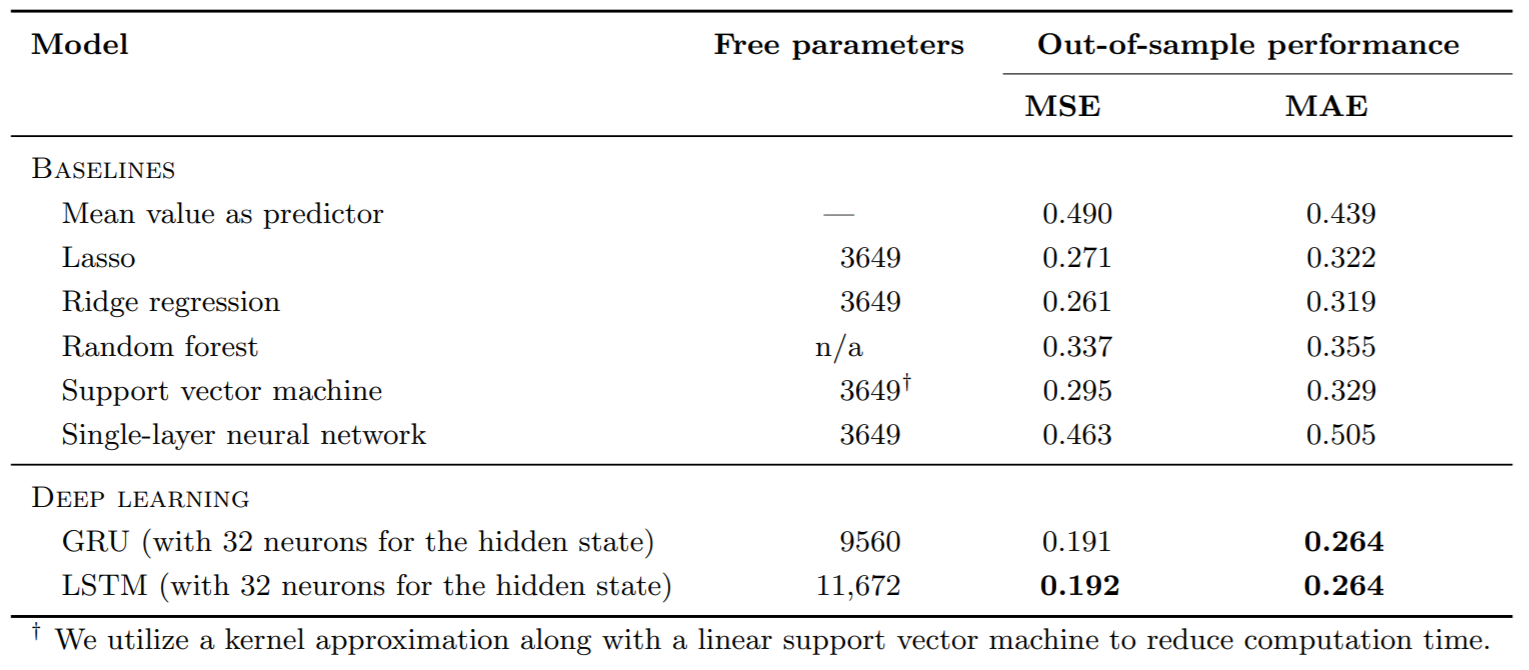
Last year researches Mathias Krausa , Stefan Feuerriegela and Asil Oztekinb compared several learning algorithms, some are classical ML algorithms, some are more complex like DL algorithms. They compare the results of those algorithms over data sete from 3 Kaggle competitions that where meant to solve classification problems. While exploring their results you could see that in some cases the difference in the accuracy between the Logistic regression with L2 regularization, which is a very classic and simple algorithm, was close to the DL, which was more expensive in terms of resources. And it’s those situations exactly that you should consider not to move from your baseline and to make a type 2 error, because this is the meaning. They wrote and article named: Deep learning in business analytics and operations research: Models, applications and managerial implications. And here are some if the results they got for the Kaggle competitions. Remember the goal was not necessarily to win the competition, only to compare the results of the algorithms been tested.
Case 1: Insurance credit scoring
Case 2: Load forecasting of IT service requests
Case 3: Sales forecasting
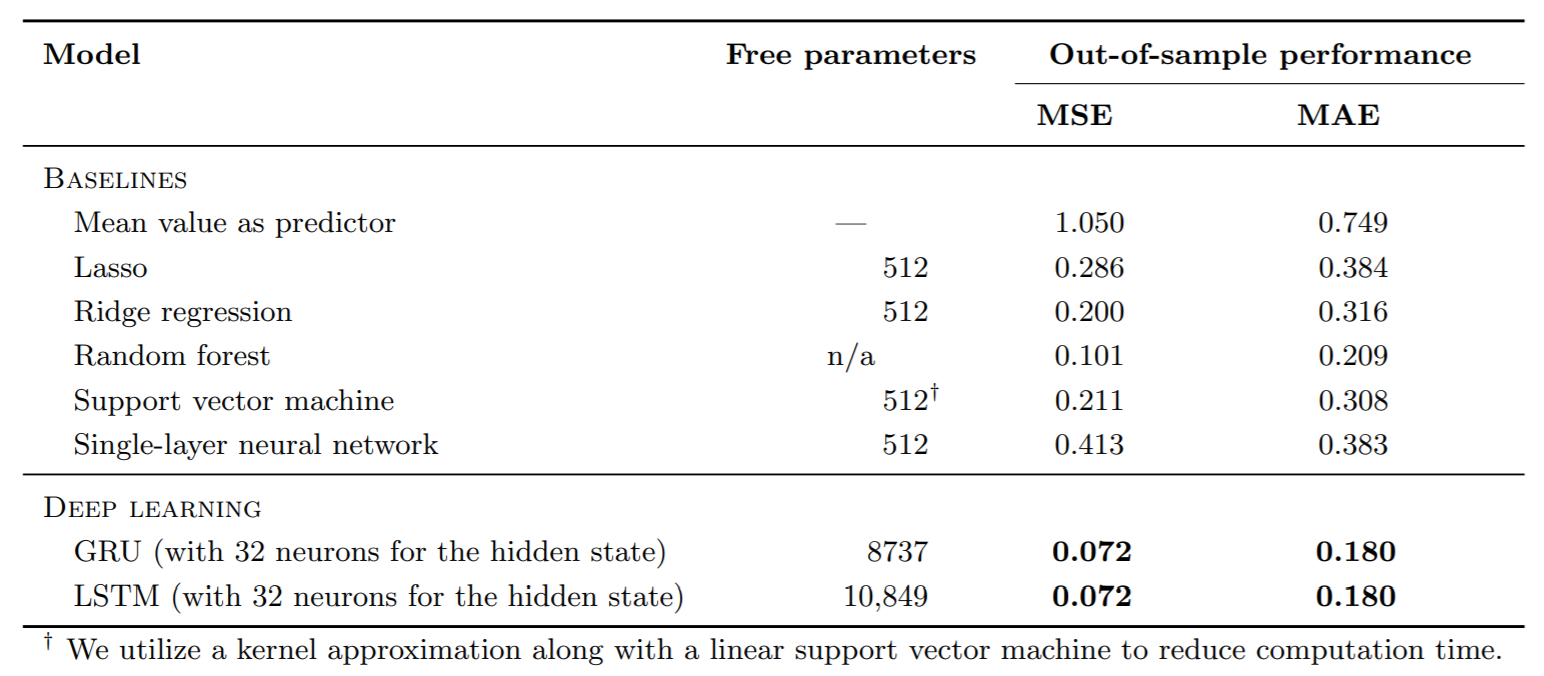
We could see that the researches used several “baselines” because their goal was to measure all the classical machine learning algorithms and compare them to DL algorithm. In your use case you could choose one or several baselines as well. We can see that in use case 1, the Logistic regression model was close to the DL so although the DL algorithm was superior, in production we wouldn’t necessarily use it.
I’m going to enhance this research and to measure the affect of the algorithm type (classical statistics, classical machine learning, new Machine learning algorithms), combined with the effect of the richness of data and problem type (classification/regression) over 60 data sets from Kaggle competitions from the business analytics domain, so we could get a sense of which algorithm type we should look for given a business problem, stay tuned, Yossi.